These 7 AI Chatbots Are Better Than ChatGPT, According To Users

OpenAI might not have invented AI chatbots, but ChatGPT certainly popularized them. ChatGPT-3.5's launch in November 2022 is widely regarded as the moment generative AI went mainstream. Suddenly, any of us could use a general-purpose large-language model (LLM), capable of human-like dialogue, and we could ask it all the stupid questions we wanted to. Within months, ChatGPT surpassed 100 million monthly active users, marking the fastest growth ever recorded for a software product at the time. But OpenAI wasn't the only player in town for very long. Within six months, Google accelerated the public release of Bard (later renamed Gemini), Anthropic launched Claude, and Meta released LLaMA.
ChatGPT was the first AI system that many people talked to directly. Its name became shorthand for AI itself, and it still dominates the AI chatbot market worldwide. So, it was a surprise that in a recent study by British company Prolific, it only placed eighth. It was bested by two Gemini models, two versions of DeepSeek, a couple of Groks, and the French AI bot — Mistral Magistral. ChatGPT usually does a bit better than that in independent rankings. According to Prolific, that's because those studies weren't testing the things that really matter. The company created its own benchmark, called "Humaine." Its blog post states, "AI evaluation has been dominated by technical benchmarks that, while important, fail to capture what people actually value."
So, what do people value? According to the study, we want chatbots that understand what we're saying, don't get confused if the conversation changes direction, give clear answers, and tell the truth.
What were the results?
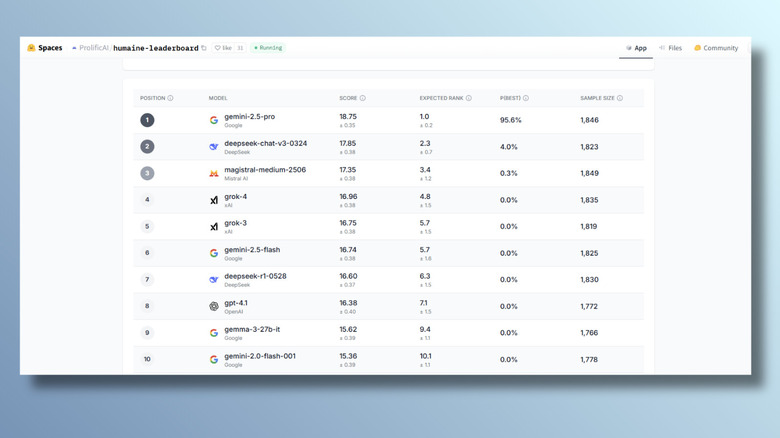
The results of the Humaine study are easily accessible on Prolific's Hugging Face page. At the time of writing, the top ten AI models on the leaderboard are:
- Gemini 2.5 Pro (Google)
- DeepSeek v3 (DeepSeek)
- Magistral Medium (Mistral AI)
- Grok 4 (xAI)
- Grok 3 (xAI)
- Gemini 2.5 Flash (Google)
- DeepSeek R1 (DeepSeek)
- ChatGPT-4.1 (OpenAI)
- Gemma (Google)
- Gemini 2.0 Flash (Google)
Scores were provided by participants who compared two anonymous models head to head. Each chatbot was assessed according to four metrics. The first, Core Task Performance & Reasoning, measured how well it answered questions and whether it seemed to understand what was expected of it. The next, Interaction Fluidity & Adaptiveness, focused on how well it could handle a multi-turn conversation. In the early days, chatbots often struggled to remember things that had just been said in a conversation. AI is now a lot better at keeping the flow of a conversation going, which provides more human-like responses.
The third metric was Communication Style & Presentation. This looked at how clearly information was presented, along with the chatbot's "personality." While some models (particularly ChatGPT) have been criticised for being too obsequious, people generally don't want responses that sound robotic. The final metric was Trust, Ethics & Safety, which is always a hot topic in AI. Participants scored chatbots based on whether the responses seemed transparent and trustworthy. They were also noting if a model produced responses that were unethical or dangerous.
Why you'd expect ChatGPT to do better

So why did ChatGPT perform so poorly here compared to Gemini, DeepSeek, Mistral, and Grok? You might expect ChatGPT to top the leaderboard given it's the most popular chatbot with the highest number of users and the most interactions. Globally, it has around 800 million active users per week. ChatGPT accounts for 48% of all AI chatbot use. There's almost as much activity on ChatGPT alone as there is on every other system combined. Other big players don't come close. DeepSeek has around 4%, Gemini and Grok both have under 2%.
Another reason you might expect OpenAI to perform well is that it was overrepresented in the Humaine study. Of the 28 models evaluated, nine were owned by OpenAI, including its omni and mini iterations. And in other studies, it scores well. For example, in 2024, scientists compared how ChatGPT-4, Microsoft Copilot, and Google Gemini all fared when completing the Italian entrance test for healthcare sciences degrees. ChatGPT performed better than its two rivals. Back in 2023, when ChatGPT was still relatively new, it demonstrated it could pass the bar exam.
On LMArena, a well-regarded public platform that ranks LLMs based on anonymous user head-to-head testing, ChatGPT currently has the fourth-highest score, after Gemini 2.5 Pro, Claude Sonnet, and Claude Opus. However, Prolific believes that LMArena's results don't tell the whole story. In a blog post about the Humaine study, it references a paper called The Leaderboard Illusion, which concluded that LMArena (then called Chatbot Arena) results were often distorted in favor of the big AI companies. This is what Prolific wanted to overcome with its own study.
What was different about the Humaine study?

LMArena's results can be distorted by tech providers finding ways to game the system. There's also participation bias because techy people are more likely to take part. Humaine's framework was built to overcome these problems. The study originally had 20,000 participants, and now has almost 25,000. Testing consisted of head-to-head comparisons, where the participants used two different anonymous chatbots and then ranked which one they thought was better. Users had multi-turn conversations about things that they were interested in or knowledgeable about so that they could assess the usefulness of the responses. The head-to-head method was selected because it's easier for people to judge performance accurately if they have something to compare it with.
A win scored 1 point and a tie scored 0.5. With 28 models in the field, the maximum possible was 27, and the field average was around 13.5. As of writing, Gemini-2.5-Pro's score is 18.75, showing that it won the majority of its rounds. The leaderboard also shows the sample size, illustrating how many head-to-head evaluations were done for each model. The higher the number, the more reliable the result. All 28 models have sample sizes of between 1,400 and 2,300. Gemini-2.5-Pro's is currently 1,846.
Participants represented multiple demographic groups in the U.K. and U.S., including age ranges, race, and political affiliation. The study showed that the biggest disparities in the results were between different age groups. While Prolific reports that "these differences were not large enough to fundamentally alter the top-level rankings," it does demonstrate that younger and older users perceive a chatbot's effectiveness differently.
Gemini takes first place on the Humaine leaderboard
Based on the feedback from the participants in the study, Google's Gemini-2.5-Pro is the best AI chatbot. It was the clear winner across multiple metrics and demographic groups. Four Google models were evaluated, so in addition to first place, the company's products also ranked sixth, ninth, and tenth. Even though the other Google products — 2.5 Flash, 2.0 Flash, and Gemma — didn't perform quite as well as Gemini-2.5-Pro, all of Google's chatbots included in the study made the top ten. Gemini 2.5 – Google's AI reasoning model — was launched in March 2025, with Pro available from June. Google described 2.5 as "a thinking model, designed to tackle increasingly complex problems."
The Humaine study isn't the only one to conclude that Gemini 2.5 Pro is the best AI. At the time of writing, Gemini 2.5 Pro also tops the LMArena leaderboard. And in an adaptive reasoning comparison carried out by AI company Vellum to determine how well AI chatbots "adapt to new contexts instead of relying on pre-learned patterns," it outranked its competitors. However, in more skills-based tests, like High School Math and Humanity's Last Exam (a language model benchmark that encompasses a wide range of subjects), it's bested by ChatGPT. The Humaine study demonstrates that Gemini excels at more subjective dimensions, like tone, clarity, and adaptiveness. Here, the scores are about more than correct answers, they reflect how well Gemini connects with users.
China's DeepSeek ranks in second place

Two DeepSeek models were included in the Humaine study, and they both did well. DeepSeek v3 came second in the rankings, and DeepSeek R1 came seventh. Back in January 2025, DeepSeek was big news. It became the most downloaded free app on the Apple App Store and the Google Play Store, with the U.S. accounting for a significant number of the total app downloads. It was noteworthy because it cost much less to build than other AI products, and got a lot of press attention. Since then, the excitement about this Chinese-built language model has died down. Its web traffic peaked in February 2025 and has been dropping ever since.
However, its impressive ranking in the Humaine study shows that it's still a chatbot worth considering. DeepSeek v3 performed well across all metrics, achieving the number one ranking for the Communication Style & Presentation category. It scores better with older users, but race and political affiliation don't seem to have any effect on its popularity.
Less well-known French company Mistral AI claimed third place
Mistral AI isn't as well-known as the other companies in the Top Ten, which makes its third-place ranking all the more impressive. Mistral's chatbot is called Le Chat, and two versions were included in the study — Magistral Medium, which is a reasoning model, and NeMo, a faster, lightweight alternative. While Magistral Medium came third, NeMo limped into 24th place. Magistral is a newer product. It was released in June 2025, a year later than NeMo's release date. This suggests that there was a huge jump in quality in that time.
Paris-based Mistral AI was founded by former employees of Google DeepMind and Meta AI. It's the most successful French AI company. In February 2025, during a TV interview, French President Emmanuel Macron urged viewers to download Le Chat. There are two versions — the one that scored well in the Humaine leaderboard is Magistral Medium, which is described by Mistral as a "frontier-class multimodal reasoning model." There's also Magistral Small, a lighter, open-source version, which wasn't included in Prolific's study.
Across the different metrics, Magistral performed particularly well with adaptiveness and communication style, suggesting that conversation flowed naturally. However, it performed relatively poorly when it came to the Trust, Ethics & Safety metric, placing only twelfth. This is particularly surprising, as we found Mistral to be one of the least privacy-invasive platforms out there.
xAI's Grok was fourth (and fifth)

Two xAI Grok models were evaluated in this study. Grok v4 came in fourth, and v3 came in fifth. This seems quite impressive, given the bad publicity Grok has gotten. Presumably, it wasn't giving the users racist and antisemitic answers like it was reported doing back in July. In fact, in the study, Grok performed particularly well when users ranked it for Trust, Ethics & Safety. This may be because some of its more dubious features have been toned down in later releases. Grok no longer seems to research Elon Musk's personal views before responding, and the chatbot's "fun mode" — designed to be swearily politically incorrect — was ditched at the end of December 2024.
And lately, Grok seems to be flourishing with the highest year-on-year growth out of any of the major chatbots. Between August 2024 and July 2025, visits to xAI's chatbot increased from 51,000 to 687 million, an increase of over a million percent. User sessions have also been found to be longer on Grok than all other language models except Anthropic's Claude, showing that its user engagement is high. In Prolific's Humaine study, Grok 4 scored higher overall than Grok 3, but the two models were pretty close, and in some metrics and demographics, version 3 outperformed the newer model. For example, when scoring the ethics metric, African Americans rank Grok 3 at the top of the list.
Overall, in terms of user experience, as measured in the Humaine study, Grok massively defeated ChatGPT. Still, OpenAI can console itself by remembering that it beat Grok in a chess tournament earlier this year.
Some chatbots performed worse than ChatGPT

ChatGPT only managing to take eighth place is noteworthy because it dominates the market in terms of both users and usage. And while no one else comes close to ChatGPT's numbers, there were some comparatively big-name players who did even worse than OpenAI in the Humaine study. Anthropic's Claude's highest placing was 11th, despite frequently scoring well in other tests, like AI company Vellum's Adaptive Reasoning benchmark, and being declared "Best Overall AI Chatbot" by CNET in August 2024.
Meta's llama chatbots scored poorly, with both models featured in the study relegated to the lower half of the leaderboard. Llama 3 came 16th, and Llama 4 ranked 23rd. Meta promised industry-leading "groundbreaking intelligence" with Llama 4, but clearly it didn't impress Humaine's participants. There were also a couple of lesser-known entries on the list. Chinese company Moonshot's Kimi came 20th, and Canadian AI startup Cohere took the 22nd and 28th spots. These poor rankings in an anonymised study suggest that they're not yet performing to the same standard as Gemini, Grok, DeepSeek, or Mistral.
Although Prolific provides extensive detail on how participants, evaluation metrics, and modeling were designed, it does not explain how or why specific chatbots were selected for inclusion in the study. We don't know why Microsoft Copilot and Perplexity are notably absent from the leaderboard.
How important is this study?

This study is still ongoing, and the results are being updated on the leaderboard, so things could change, especially as new versions and models are released. It's an important study because it doesn't just ask "which model solves the task best?" but also measures aspects like communication style, adaptiveness to user needs, trust, and safety. It's all about the human-facing side of AI. Does the model respond in a way that makes the user feel understood and listened to?
However, it doesn't replace other studies that have been carried out. There are many ways to evaluate an AI chatbot. Can it do deep research, for example? Can it do math? Or, as this article by The Guardian investigated, can it write a Shakespearean sonnet about how AI might affect humanity? OpenAI probably isn't losing any sleep over the results, largely because the ChatGPT name is now so intertwined with AI, and its usage numbers are orders of magnitude higher than anyone else's. But it shows that when people are presented with anonymized chatbot interactions, the biggest player doesn't do as well as you might expect.
Still, one compensation OpenAI can take from this is that it did win one of Humaine's "Model Awards," where Prolific singled out specific bots across six different categories for "exceptional performance." ChatGPT-o3 took the "Most Proactive" trophy for taking initiatives and suggesting follow-up actions. It's not much consolation, as Gemini romped home with four of the other awards, but still, at least it's something.